برای درک کردن "دادههای بزرگ"، ابتدا باید بدانیم "داده" چیست. فرهنگ لغت آکسفورد، "داده " را به صورت زیر تعریف میکند:
" مقادیر، ویژگیها، یا نمادهایی که توسط کامپیوتر عملیات هایی بر روی آنها انجام میشود. این داده ها ممکن است به شکل سیگنالهای الکتریکی ذخیره شده باشند و به صورت سیگنال های الکتریکی منتقل می شوند و بر روی رسانههای مغناطیسی، نوری و یا صوتی ثبت می شوند."
بنابراین، "کلان داده" نیز یک داده اما اندازه ی آن خیلی زیاد است. "کلان داده" اصطلاحی است که برای توصیف مجموعهای از دادهها استفاده میشود که حجم عظیمی دارد و با گذشت زمان به صورت نمایی رشد میکند. به طور خلاصه، چنین دادهای آنقدر بزرگ و پیچیده است که هیچ یک از ابزارهای مدیریت دادههای سنتی قادر به ذخیره آن یا فرآیند موثر بر روی آن نیستند.
مثالهایی از "کلان داده"

بورس نیویورک در حدود یک درصد از دادههای جدید تجاری را در روز تولید میکند.
تاثیر رسانههای اجتماعی
آمار نشان میدهد که هر روز بیش از ۵۰۰ ترابایت از دادههای جدید در پایگاههای اطلاعاتی سایت رسانههای اجتماعی فیس بوک وارد میشوند. این دادهها عمدتا از تصاویر، فیلم های ویدئویی، تبادل پیغام، ثبت نظرات و غیره ایجاد میشوند.

موتور جت میتواند بیش از ۱۰ ترابایت داده را در ۳۰ دقیقه از زمان پرواز تولید کند. با هزاران پرواز در روز، تولید دادهها به حجم petabytes ها میرسد.

انواع "کلان داده"
دادههای بزرگ را می توان در سه مورد دسته بندی کرد:
۱- ساختاریافته
۲- بی ساختار
۳- نیمه ساختاریافته
ساخت یافته
هر دادهای که قابلیت دخیره شدن، قابلیت دسترسی و پردازش را داشته باشد و به یک فرمت ثابت نیز باشد، به عنوان یک "داده ساختار یافته" در نظر گرفته می شود. به مرور زمان، استعدادها در علوم کامیپوتری بیشتر شد و به موفقیت های بیشتری در نکنیک های توسعه ی کار کردن با این داده های ساختار یافته دست یافته است. (که در آن فرمت به خوبی شناخته شدهاست)و همچنین ارزش خود را از آن استخراج میکند. با این حال، در حال حاضر، ما مسائلی را پیشبینی میکنیم که اندازه چنین دادههایی تا حد زیادی رشد میکند. در آینده اندازههای معمول این داده ها به چندین zettabyte خواهد رسید.
آیا میدانید؟.
زتابایت به انگلیسی: Zettabyte یک واحد از اطلاعات که برابر ۱۰۲۴ اگزابایت است. کوتاه شده آن (ZB) میباشد.
۰۰۰ ۰۰۰ ۰۰۰ ۰۰۰ ۰۰۰ ۰۰۰ ۰۰۰ ۱ بایت = ۱۰۰۰ به توان ۷ یا ۱۰ به توان ۲۱ !!!
با نگاه کردن به این ارقام بزرگ، به راحتی میتوانید درک کنید که چرا نام "کلان داده" به آنها اختصاص داده شده و چالشهای موجود در ذخیرهسازی و پردازش آنها را تصور میکنید.
آیا میدانید که دادههای ذخیرهشده در یک سیستم مدیریت پایگاهداده رابطهای، یک نمونه از دادههای "ساختار یافته" است؟!
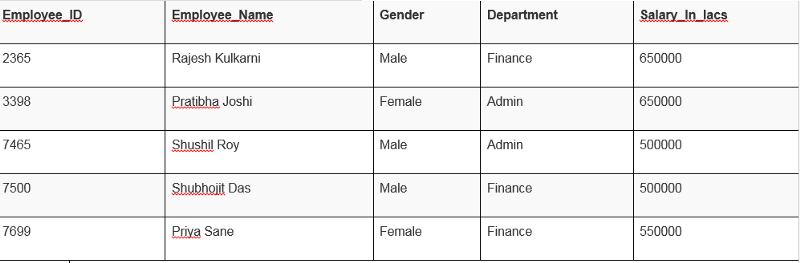
مثالهایی از دادههای ساختاریافته
یک جدول از مجموعه ای "کارمند" در پایگاهداده، یک نمونه از دادههای ساختاریافته است.
داده های بدون ساختار
هر دادهای با فرمت یا ساختار ناشناخته، به عنوان دادههای بدون ساختار طبقهبندی میشود. دادههای بدون ساختار علاوه بر داشتن اندازه بزرگ، ، چالشهای متعددی را از نظر پردازش آن برای استخراج ارزش آن داده ها، به وجود میآورد. نمونه بارز دادههای غیر ساختاریافته، یک منبع داده ناهمگن که شامل ترکیبی از فایلهای متنی ساده، تصاویر، ویدئوها و غیره است. در حال حاضر، سازمانهای امروزی روزانه سرمایه ای از داده ها را در اختیار دارند، اما متاسفانه نمیدانند چگونه از آنها استفاده کنند و اطلاعات ارزشمندی را از آن داده ها استخراج و استنتاج کنند؛ چرا که این دادهها در قالب خام و یا بدون ساختار قرار دارند.
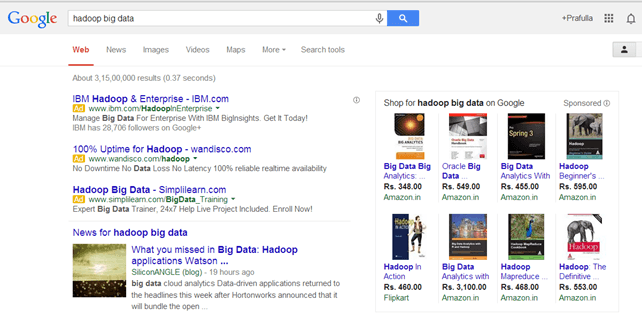
مثالهایی از دادههای غیر ساختاریافته
خروجی که توسط "جستجوی گوگل" بازگردانده می شود
داده های نیمه ساختار یافته
دادههای نیمه ساختار یافته میتوانند هر دو نوع داده (ساختار یافته و غیرساختاریافته) را شامل شوند. ما میتوانیم دادههای نیمه ساختار یافته را به صورت ساختاریافته ببینیم اما این داده ی نیمه ساختاریافته، به صورتی که بخواهیم آنها را به عنوان یک جدول رابطه ای در نظر بگیریم، در DBMS تعریف نشده است.
مثالی از دادههای نیمه ساختار یافته، می توان به داده هایی که درون یک فایل XML است اشاره کرد.
مثالهایی از دادههای نیمه ساختار یافته
اطلاعات شخصی ذخیرهشده در یک سند XML –

رشد داده در طول سالها
لطفا توجه داشته باشید که دادههای کاربردی وب، که بدون ساختار است شامل فایلهای لاگ، فایلهای تاریخچه معامله و غیره است. سیستمهای OLTP برای کار با دادههای ساختاری ساخته میشوند که در آن دادهها در روابط (جداول)ذخیره میشوند.
ویژگیهای "کلان داده"
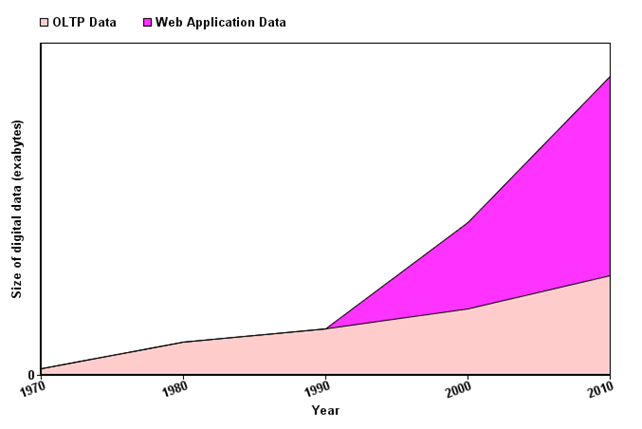
لطفا توجه داشته باشید که داده های برنامه های وب، که غیرساختاریافته هستند متشکل از فایل های log ، فایل های تاریخچه ی تراکنش ها و ... می باشد. سیستم های OLAP برای کار کردن با داده های ساختاریافته ساخته شده اند که در آن داده ها در روابط(جدول ها) ذخیره می شوند.
۱) حجم (Volume)
نام "کلان داده" مربوط به اندازهای است که بسیار زیاد است. اندازه دادهها نقش بسیار مهمی در تعیین ارزش دادهها دارد. همچنین، این که آیا یک داده خاص میتواند به عنوان یک داده ی بزرگ در نظر گرفته شود یا نه، وابسته به حجم داده ها می باشد. بنابراین، "حجم" یک ویژگی است که باید در هنگام برخورد با "کلان داده" در نظر گرفته شود.
۲) تنوع (Variety)- ویژگی بعدی کلان داده ها ، تنوع است.
تنوع به منابع ناهمگون و ماهیت(طبیعت) دادهها، هم ساختار یافته و هم غیرساختاریافته، اشاره دارد. در گذشته ای نزدیک، تنها منبع داده ای که مورد توجه بیشتر برنامه ها قرار داشتند، صفحات گسترده و پایگاه های اطلاعاتی بودند. در حال حاضر، دادهها به شکل ایمیلها، عکسها، ویدیوها، دستگاههای نظارتی و کنترلی،فایل های PDF، صوت و غیره در برنامه های تجزیه و تحلیل در نظر گرفته میشوند. این تنوع داده های غیرساختاریافته ، مسایل خاصی را برای ذخیرهسازی، استخراج و تحلیل دادهها ایجاد میکند.
۳) سرعت(Velocity)- عبارت سرعت، به سرعت تولید داده ها اشاره دارد.
این که داده ها چقدر سریع تولید و پردازش میشوند تا نیازها را برآورده کنند، پتانسیل واقعی را در دادهها مشخص میکند.
سرعت کلان داده ها، به سرعت جریان داده از منابعی مانند فرایندهای کسبوکار، لاگ های اپلیکیشن ها ، شبکهها و سایتهای ارتباط جمعی، حسگرها، تلفن های همراه و غیره جریان دارد. (رشد) جریان داده ها بسیار عظیم و مداوم است.
۴) تغییرپذیری (Variability)
این امر به ناهماهنگی ایجاد شده توسط دادهها در زمانهای مختلف اشاره دارد، در نتیجه مانع از پردازش و مدیریت موثر داده ها می شود.
مزایای پردازش دادههای بزرگ:
توانایی پردازش "دادههای کلان" مزایای چندگانهای دارد، مثلا -
· کسب و کارها میتوانند در هنگام تصمیمگیری از هوش خارجی استفاده کنند .
دسترسی به دادههای اجتماعی از موتورهای جستجو و سایتهایی مانند Facebook، سازمانها را قادر میسازد تا استراتژیهای کسبوکار خود را تنظیم کنند.
· بهبود خدمات مشتری
سیستمهای بازخورد(فیدبک) مشتری که به صورت سنتی انجام می گرفتند، سیستمهای جدیدی جایگزین آنها میشوند. این سیستم های جدید با تکنولوژیهای "کلان داده" طراحی شدهاند. در این سیستمهای جدید، از فناوریهای کلان داده و پردازش زبان طبیعی برای مطالعه و ارزیابی واکنشهای مصرفکننده استفاده میشود.
· شناسایی اولیه ریسک برای محصول / خدمات
· کارایی عملیاتی بهتر
مطالب زیر ممکن است برای شما مفید باشد
تگ های header را در سئو سایت دست کم نگیرید رادیو صفر و یک - پادکست شماره ی 9 ام - اینترنت بی اینترنت رادیو صفر و یک - پادکست شماره ی 3 ام - شرکت جت برینز و محصولاتش برای برنامه نویسان رادیو صفر و یک - پادکست شماره ی 5 ام - دیپ فیک چیست ؟ آخرین مرز میان حقیقت و دروغ رادیو صفر و یک - پادکست شماره ی 1 ام - معرفی رادیو صفر و یک و زندگینامه ی گوینده
محصولات برگزیده مناسب شما
کارگاه آموزشی نحوه ی آپدیت ورژن فریمورک laravel کارگاه آموزش کار با API های اینستاگرامی دوره ی آموزش ساخت اپ گالری تصاویر آنلاین با کاتلین کارگاه آموزشی کار با Grunt js
پایان 👍
